- Recurring Themes
- Some definitions
- Process for launching your program
- Bugcrowd’s triage SLOs
- Promoting a program successfully
- Expectations from a program over time
- What to do if you run out of money in your reward pool
- Some quick links/resources to getting started
- Once your program is live
- Common reward ranges and growth paths
- Using Bugcrowd’s VRT (Vulnerability Rating Taxonomy)
- The need to import known issues
- Risks with changing the program brief after program launch
- Provisioning credentials
- Managing one’s testing environment
- What to do if your hosted by a third-party such as AWS, Azure, or Google Cloud
- Support Resources
Welcome! This page shares frequent requested details.
Recurring Themes
As you go through this doc, you’ll note a few recurring themes that tend to come up fairly often, namely:
1. How to work with Researchers
Please be mindful that Researchers have a choice about how to spend their time and effort. When building and managing your program, ask yourself whether you would enjoy working under the circumstances you have set for Researchers. If you have questions about how to foster a strong relationship with your researchers, read on!
2. Your role in a Managed Service
Bugcrowd’s managed services are designed to reduce the amount of resources and time you have to expend on your program; that said, it’s still important to understand the role you play in ensuring continual program growth and success. Our team is skilled in understanding the levers of program health, and will periodically advise when further actions or decisions are needed on your part. The more proactive you are during this process, the more likely you are to see better results from the program as a whole.
3. Data-based decisions
Bugcrowd has run over 500 managed programs to date, which has helped us amass a hefty repository of program success metrics. Please understand that all of the advice outlined in this document is based in our deep understanding of how to effectively manage outstanding programs for our customers.
Some definitions
Crowdcontrol is the official name of Bugcrowd’s platform that can be found at https://tracker.bugcrowd.com/. This portal is where you’ll setup and manage your program on Bugcrowd.
The Program Brief is a single page, researcher-facing document that contains all the relevant information regarding your bounty program (what’s in/out of scope, rewards, how submissions will be rated, instructions for accessing or testing the application, etc). For examples of current public bounty briefs, visit https://bugcrowd.com/programs. After the initial kickoff call with your Solutions Architect, we’ll work with your team to create a concise and effective program brief.
Bugcrowd’s Vulnerability Rating Taxonomy, or VRT, is the basis by which we rate the technical impact of findings, and thereby assign relative priorities that range between critical (P1 - highest reward), to informational (P5 - no reward). Prior to launching any program, it’s important to familiarize yourself with this taxonomy, which can be found at https://bugcrowd.com/vrt, as your organization may have different preferences regarding the prioritization or rating of particular vulnerability types. This taxonomy may be modified to your individual needs as you see fit – be sure to discuss any deviations with your Solutions Architect, as well as documenting those changes on your bounty brief.
Process for launching your program
1. The people you’ll be working with
-
Solutions Architect (SA) - Your technical point of contact who will cover scoping out the program, as well as helping build the Program Brief. They will be the primary point of contact during the setup period, and will re-engage for any future technical questions.
-
Account Manager (AM) - After the program is live, the day-to-day communication and regular check-ins will be managed by the AM. They’ll work collaboratively with you and your team to the grow and mature the program over time. The Account Manager is also responsible for the renewal and most contract related topics.
-
Application Security Engineer (ASE) - This is the person who will be triaging all the inbound findings into your program - most Program Owners work very closely with their ASEs, and if you have any questions regarding submissions, they’ll typically be answered by the ASE directly on the submission itself via comments. Sometimes there will be multiple ASEs on a single program.
2. The timeline for going live
- Day 0: Introductions via email + setting up a kickoff call.
- Day 1 - 3: Kickoff call between yourself + your Solutions Architect
- Program scope/expectations, as well as a tentative/targeted launch date will be covered during this conversation.
- Day 3 -7: Collecting/setting up any outstanding action items as a result of the kickoff call.
- Day 5 - 7: All things collected and in-hand one week prior to the targeted launch date, Bugcrowd will confirm the launch, and organize a platform walkthrough.
- Day 10-12: Program launch + platform walkthrough call + scheduling a post-launch sync for one week after launch.
- Day 15 - 17: Post-launch sync to discuss program adjustments, learnings, growth plan, and re-introducing the Account Manager who will be the primary point of contact going forward.
If it hasn’t happened already, shortly after purchasing Bugcrowd, you’ll be introduced to your Solutions Architect by either your Account Executive or other member of your account team.
Bugcrowd’s triage SLOs
Bugcrowd maintains the following SLOs:
- Any P1 (critical) issues will be actioned within one business day (and if valid, will be escalated to the client).
- Our ASE will action any new submissions within three business days (note that actioning a submission does not imply that it will be triaged, as sometimes the action that’s needed is to get more information from the researcher, etc).
All of the above are offered in the context of standard business hours for Pacific Time Zone (e.g. Monday-Friday, 9am-5pm); and company/Federal Holidays are explicitly excluded from any SLO time period. Triage and Payments will not be processed on non-business days.
In addition to our Standard SLO, Bugcrowd offers the option to upgrade to a premium SLA. There are two options to choose from.
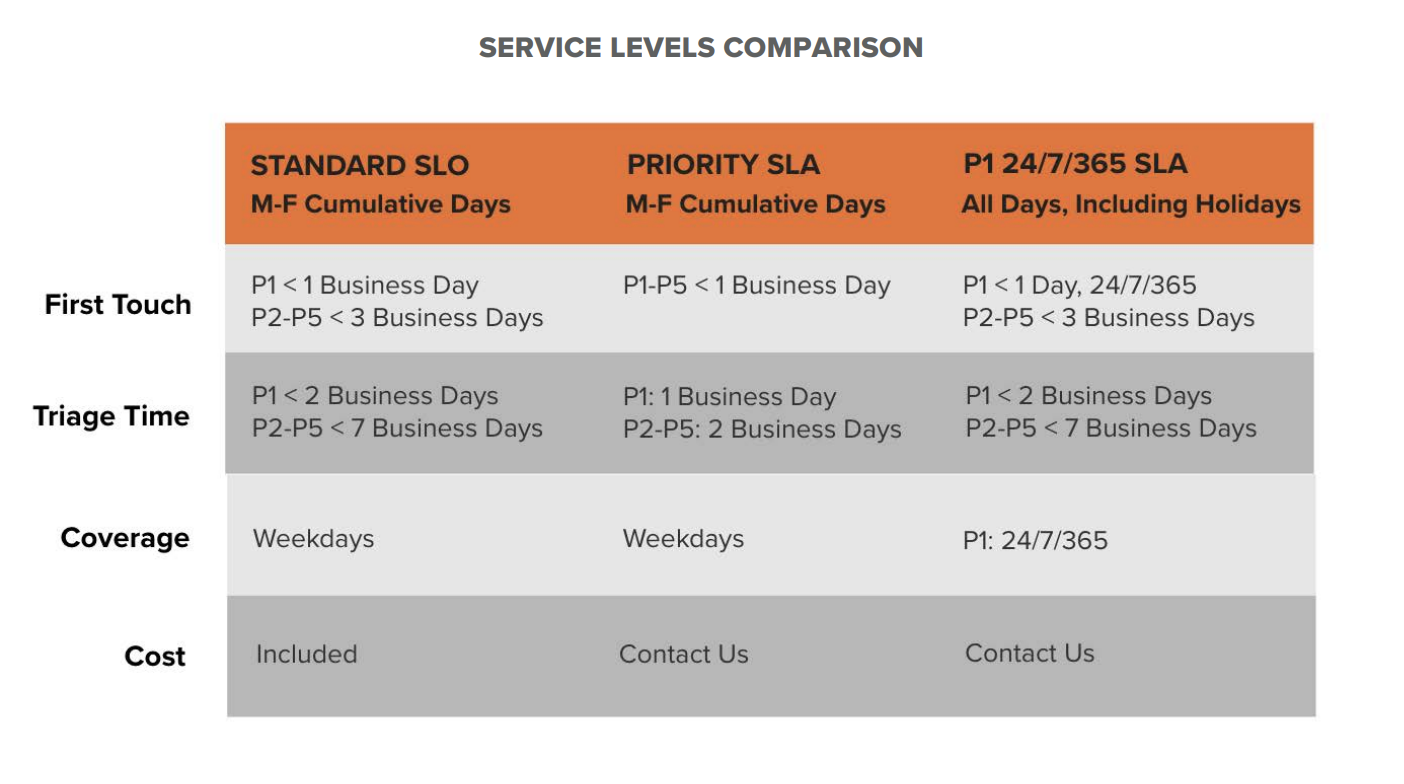
We’ll work with your team to recommend the service level that best meets your goals and expectations. For more information and pricing, please contact your Account Manager.
For those programs with vulnerability triage packages including non-business days, triage will be included as specified. For information about the non-business days, see Bugcrowd non-business days.
We ask customers to maintain the following SLOs:
- Accept triaged submissions within seven days of being moved to ‘triaged’ by the Bugcrowd team.
- If you expect it to take longer than one week for a submission to be accepted, please leave a status update in the form of a comment to the researcher - this enables them to plan their time accordingly, etc. Please be aware that lengthy delays in accepting submissions is heavily correlated with diminished researcher participation, and lower total volume over time.
Pro-tip: It’s a good idea to have at least two program owners on any given program - doing so ensures that if one is not available, that there’s coverage. Furthermore, having two persons also ensures items get handled in a more expedient manner.
Promoting a program successfully
We recommend starting with this blog post: https://www.bugcrowd.com/blog/5-tips-and-tricks-for-running-a-successful-bug-bounty-program/. We also recommend keeping FRUIT in mind. FRUIT is an acronym that highlights some core characteristics of an effective Program Owner. An effective Program Owner is:
-
Fair - Executing on the expectations set on the program brief, and rewarding researchers for their effort. Remember that your bounty brief is essentially a contract between your organization and the researchers, and it is ultimately your responsibility to ensure that the content accurately reflects the information you want to be conveyed to researchers.
-
Responsive - Rewarding findings in a timely fashion (ideally, never more than seven days), and quickly responding to any questions from Bugcrowd or the researchers. Lengthy response times jeopardize researcher goodwill and interest in participating. As noted in the customer SLO section, we highly recommend having at least two program owners to helps ensure continuity.
-
Understanding - Recognizing that researchers are here to help. Treat them with the same respect that you would if they were an extension of your own team- because they are!
-
Invested - Doing what it takes to make a program successful - whether that means getting more credentials, increasing rewards, sharing changelogs, or increasing the scope. Our most successful programs are led by deeply invested Program Owners. An additional corollary to this point is to recognize that we want researchers to find vulnerabilities! Creating an environment that is conducive to this goal means being open to working with your Account Manager on broadening access to more parts of your target for testing purposes.
-
Transparent - Being clear and honest with researchers. If something is downgraded or not an issue, offering a full and clear explanation helps the Researcher to appropriately refocus their efforts. For programs with reward ranges, it’s invaluable to provide extensive detail about submission types that map to each reward band.
Expectations from a program over time
Your program will need to grow over time. “Set-and-forget” is not a phrase that applies to any successful program. Running a program requires continual investment and involvement. We’re well versed in adjusting as needed to promote optimum results, so we only ask that you be an active participant in this process.
Relationships are everything
Few things are more impactful to your program than the relationships you have with the people who make it a success; namely, the researchers themselves, the ASEs who work on your program, and your account team at Bugcrowd. Like your own team of engineers, Researchers want to be assured that their efforts have impact. Those who understand their role in the SDLC are far more likely to continue focusing their efforts on your program - going deeper than others, and coming back for more over time. The relationships you build here will pay dividends well into the future (remember: we want to help researchers find issues). Furthermore, collaboratively working with your Bugcrowd team (ASE/AM/etc) will help us help you have the best possible program.
Crawl, walk, run
We guide all programs according to a crawl, walk, run model. This means that no program starts with hundreds or thousands of researchers - though, where possible, that’s certainly where we’d like to end up. We take scaling effectively, seriously, and want to ensure solid foundations and mechanics first. To this end, all programs, even the most advanced, start as relatively small private programs, and we ramp them (at varying speeds) towards whatever the desired final state is.
Controlling the ebb and flow of Researcher Activity
Most programs experience the highest level of researcher activity during the first few weeks. As such, this period is a critical time to demonstrate to researchers your level of involvement. Many researchers will report one bug, gauge the experience with the Program Owner, and then make a determination as to whether or not they will continue with the program.
Three levers
As the program goes on, and the low hanging fruit is picked clean, we look to three primary levers to ensure continued value: a) Reward levels; b) Number of researchers; and c) Program scope (as well as sharing what’s been changed/updated in relation to the target). Our team is experienced in identifying which to push, and when, in order to promote success as your program matures.
Going public
Sometime after demonstrating success with a Private program, your Account Manager may recommend taking the program Public in order to continue to recruit new and varied Researcher involvement. This will involve opening your program to the broader Bugcrowd Researcher community - more eyes on your program equates to more available skills, and subsequently better results This is the fundamental tenet of crowdsourced security - five will always find more than two, fifty will find more than five, and five hundred - well you get it…
Reframing your program’s purpose
Over an extended period of time, as vulnerabilities are surfaced and remediated, we expect a reduction in the number of submissions. Hopefully your team will have also experienced positive changes in workflow, remediation practices, your relationship with the Development team, and perhaps their best practices as well. All of these factors contribute to reducing risk and thus overall program submissions. At this point it’s important to reframe the role your program will play in your broader success plan. Where previously the program may have served as a primary identifier of issues, over time it may shift down the line of defense and find its greatest value as a place for persons to responsibly disclose issues as they sporadically arise.
What to do if you run out of money in your reward pool
If you happen to run low or out of funding for your program, contact your account team (e.g. your AM) to request a purchase order for an additional amount of your specification.
Your team may also reach out if your program dips below a certain threshold to proactively get your pool replenished.
Some quick links/resources to getting started
The following will help you become acquainted with the Crowdcontrol platform:
- Where to login to Crowdcontrol: https://tracker.bugcrowd.com/
- How to setup the Jira integration (if applicable)
- How to setup SSO (if applicable)
- Information regarding notifications settings
- How to import known/pre-existing issues
- How to add/remove users on the platform
- How to update the program brief
Once your program is live
Once your program is up and running, you should be prepared to start receiving submissions. For reference, here’s a brief overview of the general submission workflow.
1. Researcher Submits
A new submission is submitted, represented as the “new” state, and shown as the “processing” tab on the submissions page.
2. ASE Triage
A Bugcrowd Application Security Engineer (ASE) reviews the submission and verifies that it is valid, replicable, in-scope, and not a duplicate.
If the ASE has a question for you (the client) that needs resolution before they can triage the finding (e.g. “is this intended functionality”), they’ll identify it via a blocker. For more information about blockers, see submission blockers, and can check for blockers that need your attention by visiting this URL: https://tracker.bugcrowd.com/<program-code>/submissions?blocked_by[]=customer
3. ASE moves submission to be reviewed
If all these criteria are met, the ASE assigns a priority to the submission based on the pre-defined rating system/taxonomy and moves the submission into the triaged state (which is shown as “to review” on the submissions page).
4. Customer Review
Anything in the triaged state (aka the to review tab) is something that now needs to be reviewed and accepted by your team.
- The recommended and expected timeline for accepting submissions is one week; if you expect it to take longer than this for a submission to be accepted, please leave a status update in the form of a comment to the researcher - so they have context for how long they can expect to wait, etc.
- In reviewing the submissions, please ensure that the assigned priority is aligned with your valuation - additional information regarding changing priorities, see submission priorities.
5. Customer Accepts
Once you agree that you intend to fix and reward the submission, you can accept the finding by updating the state to unresolved - which, as one would assume, then moves the report to the unresolved state, which is shown as to fix tab on the submissions page). For additional information regarding changing submission states, see submission status.
If you have any questions regarding a submission that’s in the to review bucket, feel free to leave an mention via a team note for our an ASE via @bugcrowd - or directly reach out to the researcher via the reply option.
6. Customer Rewards
Upon moving something to unresolved (if this is a paid program), a reward modal will show and ask that you provide a reward. Please reward the submission at a dollar amount that’s consistent with what’s listed on the program brief (there will be some assistance in this regard from the pop-up, which will suggest an amount that aligns with the set priority of the finding. If the suggested amount does not align with your expectations, please let your AM know, and we can adjust accordingly)).
As soon as a submission is set to unresolved the researcher gets an email that notifies them of the bug’s acceptance and their pending reward (where applicable).
7. Customer Fixes
Once the bug has been fixed, be sure to move it to resolved so that we can catch any potential regressions that may occur after the fix has been implemented. This usually happens days to weeks after the submission has been accepted, etc.
Common reward ranges and growth paths
Many first time program owners tend to adopt the perspective of “wow, $20,000 for a P1 is a lot of money - can we pay less?” - To which, we advise engaging in this short exercise:
-
Imagine you get breached tomorrow by a P1 level vulnerability (SQLi, RCE, etc), leaking a substantial amount of client and/or internal information on the web.
-
Considering you’ve been breached and it’s all over the news, does $20,000 still seem like too much to pay to know about the critical issue before it happens?
-
If knowing about the issue in advance isn’t worth at least $20,000, then by all means, pay less - but know that in most cases, individuals would gladly pay 20 times that amount for the luxury of knowing about the issue before it got exploited. Keeping this in mind, it’s probably even a good idea to pay more than $20,000 for a P1.
Know that you only ever have to pay the max reward for an actual P1 finding. There are no false positives in bug bounties - you only pay when you’ve validated and accepted the issue. If there are no P1 issues, you never have to pay that amount. Hopefully this exercise helps guide you with setting effective reward ranges.
While non-exhaustive, the following list details our recommended starting reward ranges and corresponding example target types:
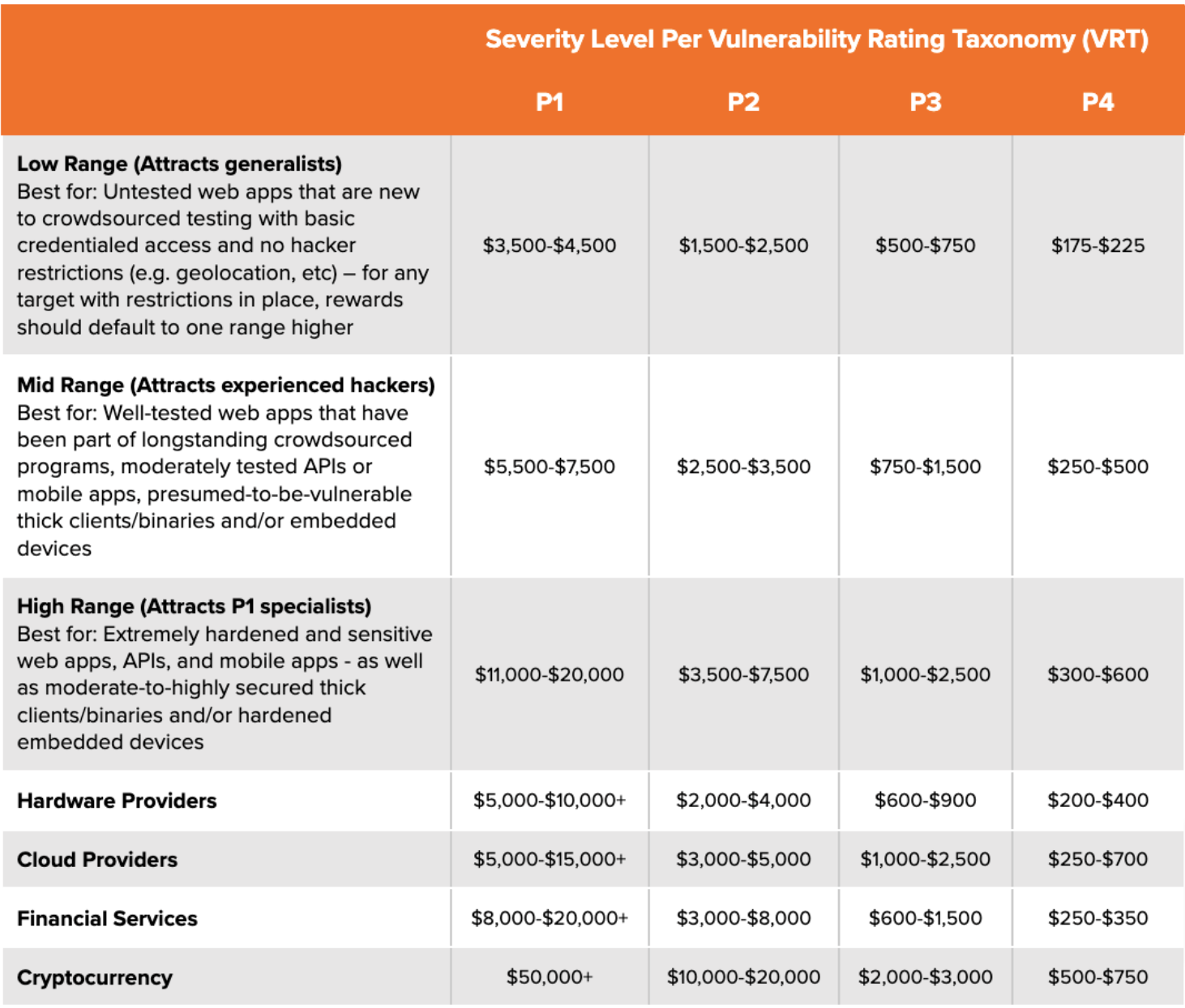
The typical growth path largely mirrors a progression of the above ranges. However, as noted in the FAQ in what to expect over time, there’s also a mention of three distinct levers that can be used to help grow a program over time. The following is an example of an untested web app’s program growth plan over the course of a year:
-
Day 1:Scoping/kickoff call with Bugcrowd -
Day 14-21:Program goes live with X # of researchers with a $175-4500 reward range -
Day 30:Post-launch sync to assess what steps to take going forward -
Day 45-60:Depending on submission volume, add an additional X researchers to the program -
Day 75-90:Increase rewards to $300-20000 (this typically happens once the program crosses either the 50 or 100 person threshold; depending on the starting point); if additional scope is available, add it - as further scope becomes available, it should be added -
Day 120:Setup a cadence of 25 additional researchers every other week -
Day 150:Start planning for going public after hitting ~200 researchers on the program; increase rewards on the added attack surface -
Day 180:Increase scope to additional (or for small organizations, all) assets owned by the organization -
Day 210:Go public -
Day 260:Increase rewards, share updates/code changes as they happen, and iterate as needed.
Using Bugcrowd’s VRT (Vulnerability Rating Taxonomy)
Bugcrowd’s VRT is something we’ve collectively built and refined over the course of hundreds of bounty programs. It is a classification system for ranking known vulnerability types as P1 (critical), P2 (high), P3 (medium), P4 (low), or P5 (informational). These priority levels correspond to set reward ranges on the program brief, which determines the range in which a given finding gets rewarded. You can review the VRT here: https://bugcrowd.com/vulnerability-rating-taxonomy. The VRT is open source - and thus open to community suggestions/contributions - which happen regularly. Based on conversations with the community, we then update and adjust the VRT as needed (with major changes pushed once a quarter). You can review the VRT on GitHub here: https://github.com/bugcrowd/vulnerability-rating-taxonomy.
The VRT is an industry standard that we encourage all program owners to abide by. Leveraging the VRT enables Program Owners to implicitly signify discrete reward ranges for known vulnerabilities, thus removing any ambiguity for participating Researchers. This saves you from having to enumerate every possible vulnerability (and the associated reward amounts), as well as preventing confusion from researchers around how things should be rated, or even what should be submitted!
Deviations from the VRT are perfectly acceptable, though we encourage a auxiliary enumeration of your deviations, as opposed to trying to build a new taxonomy on your program brief (which can get long, messy, and complicated). If you wish to exclude one particular finding type, note on the brief that “this program follows the Bugcrowd VRT, except for X thing, which will not be rewarded.”
The need to import known issues
It’s often the case that many program owners have done some degree of security testing prior to running a bug bounty program (e.g. via pentests, internal testing, automated scanning, etc). Provided all the findings haven’t been remediated by the time the program starts, you likely don’t want to have to pay out for issues that you already know about - which is the function of importing known issues. By uploading your known issues to the platform prior to the program start, it allows our ASE team to de-dupe against those findings, and also provides researchers with a level of trust and visibility that issues marked as duplicate truly existed prior their report, as opposed to relying on the less effective strategy of asking the researcher to “trust us”.
When importing known issues, there are a few options:
-
List out the known issues on the program brief. This is an extremely helpful and well-regarded show of good faith for researchers. Rather than ending up in a situation where they may hunt for a while only to find a duplicate finding (which, as one could imagine, can be disheartening), by explicitly listing out the known issues on the program brief, it allows researchers to focus their efforts on finding and reporting things that you don’t already know about.
-
Import the known issues into the platform via CSV or API. For details, see importing known issues. Of particular note, when importing known issues, it’s incredibly important that you include enough information for our ASEs to be able to fully replicate the findings, and be able to de-duplicate based on the provided information. For instance, if importing an XSS finding, instead of saying “XSS on example.com/example/”, the description should state the vulnerable parameter, the injection used, any steps to reach the vulnerable functionality, and so on.
-
Choose not to import any known issues. However, in doing this, please be aware that the expectation from both the researcher side as well as Bugcrowd’s, will be that all valid, in-scope findings will be rewarded, even if they’re already known on your end.
Risks with changing the program brief after program launch
We recommend exercising a high degree of caution whenever editing a program brief after the program has gone live.
In any case where you’re materially changing the program brief (e.g. modifying scope, changing rewards, etc), it’s strongly advised that you first share these changes with your primary point of contact at Bugcrowd (usually your AM) to
- Get their feedback and input in regards to the fairness and relevance of the changes
- Allow your Bugcrowd rep the opportunity to simultaneously send out an update to all the participating researchers - ensuring they’re made aware of the impending changes.
Failing to do this often results in severely misaligned expectations between customer and researcher, and risks degrading the relationship thereof.
It is ultimately your responsibility to ensure that the program brief accurately represents your expectations before it goes live. Common post-launch changes include removing rewards or moving particularly vulnerable targets to out-of-scope, downgrading certain vulnerability types, and so on. To be clear, it’s perfectly acceptable to make these changes, but please always do so in conjunction with Bugcrowd, so we can make sure the communication goes out to researchers, as well as our ASE team (so they’re aware of the new changes as well).
Ideally, for any material brief change, we recommend:
- Send an email to your AM with your suggested scope change/update.
- Your AM/SA will review the proposed changes, make any salient recommendations.
- Once the changes are agreed to by both sides, you (or your AM) will update the brief and where necessary, also send out program update.
Provisioning credentials
-
Testing on apps without any authenticated access (e.g. marketing sites/etc) will often result in a low number of submissions and activity, since there’s little to no dynamic functionality for researchers to test against. When selecting targets, authenticated targets will almost always be more attractive and meaningful assets to have to tested as part of a bounty program.
-
If there is an authenticated side of the in-scope application, we should make every effort to provide credentials to researchers. Similar to the above, testing something without credentials, while it may seem “black-box”, is an ineffective way of truly understanding the relative security of an app, as well as identifying vulnerabilities (which is our goal - remember, we want to find issues).
-
If we are able to have credentials, we typically ask for two accounts per researcher, so as to allow for researchers to be able to perform horizontal testing. Without two sets of credentials, we potentially leave an entire class of issues off the table (IDORs, most notably). Having two sets will often lead to findings, and is highly recommended, even at the cost of fewer total testers. One notable exception here, is if we’re able to provision each researcher with a single high-priv user with which they can then self-provision additional users as needed. In which case, one set is ok.
-
In line with the above, a general guiding rule around credentialed access for researchers is that the more attack surface we can put in front of researchers, the more likely we are to find issues. With this in mind, we always want to provide researchers with as high of a level of access as we’re able to. Instead of giving all researchers low-priv users, we should give them both low priv and high priv users - allowing them to attempt privilege escalation attacks, and enabling them to test the most functionality possible.
-
Sharing credentials is never a recommended or ideal practice, and should be avoided whenever possible. Shared credentials will almost always end badly. All it takes is one researcher accidentally changing the password, and then everyone is locked out - losing their momentum and interest, and are unlikely to return to full steam even when the issue is resolved.
-
If this is a multi-tenanted application, we ideally want to give researchers access to two tenants (or organizations), so they can do cross-tenant testing - and in an ideal world, each researcher would have their own tenant. The goal of this is that not only do we want researchers to be able to be able to perform horizontal testing inside their own org, but we also want to ensure that they’re also able to do cross-org testing.
-
Understand how many total sets of credentials will be able to be created and handed out to researchers over the course of the program (is it limited to 25? 50? 500?). This number will inform the maximum number of researchers and often the starting crowd size as well. As noted above, we ideally want to provide two sets per researcher, so this should be considered when thinking about how much runway we have in terms of credentials.
-
If live/actual personal information is required of researchers for them to setup accounts (credit card numbers, social security numbers, etc), this can often be a deal breaker for many researchers, and should be avoided if possible. This is often a very good reason to use staging, since accounts can often be pre-populated independent of actual user info. Finding a way around any barriers to entry is important in being able to get researchers involved and activated.
Managing one’s testing environment
Where possible, we suggest utilizing pre-production/staging environments, as opposed to production. However, in situations where production makes the most sense, we’re always in favor of whatever provides researchers with the best chance of success - whether that’s production, staging, or however else the target is accessed.
This in mind, there are a number of benefits to not testing against production, some of which being:
- There’s usually no customer PII present on non-prod environments (in the case that someone finds a vulnerability that exposes other user’s data).
- There’s no chance of affecting actual users if the staging environment is made unstable from researcher testing.
- If there’s anything to be purchased on the application, it’s usually a lot easier to provision fake credit cards/SSNs/etc on non-prod environments.
- Testing against a staging/non-prod app can allow us to test against a newer version of the app before it hits production - thereby identifying issues before they’re exposed to the public.
- It’s typically easier to mass create credentials for researchers to test with.
- It’s similarly much easier to restrict access to only testing researchers (only allowing access from a specific IP address, etc) - thereby providing better visibility into researcher testing/coverage.
What to do if your hosted by a third-party such as AWS, Azure, or Google Cloud
It is your responsibility to file any relevant or required pentesting requests through whichever vendor you utilize. Here are some common vendors and their policies (always double check with your vendor, as policies can and do often change.)
Google Cloud: As of December 2018, Google does NOT require any formal pentesting request to be filed, noted here: https://support.google.com/cloud/answer/6262505?hl=en.
Azure:: Review the guidelines here: https://docs.microsoft.com/en-us/azure/security/fundamentals/pen-testing.
As of December 2018, Microsoft does NOT require any formal pentesting request to be filed. However, make sure to follow the pentest rules of engagement provided at https://www.microsoft.com/en-us/msrc/pentest-rules-of-engagement?rtc=1.
AWS: Review the guidelines provided at https://aws.amazon.com/security/penetration-testing/.
Support Resources
- For any other questions or issues, visit the Bugcrowd Customer Support Center or submit a support ticket through the Bugcrowd Support Portal.